
My first instinct, whenever I’m using an AI coding assistant, is to follow along with every step. Guide it, redirect it when it drifts, catch mistakes before they compound. It feels responsible. But it also puts the human squarely inside the AI’s feedback loop — which defeats a lot of the point.
Recently, a few colleagues and I started an experiment to find out what happens when you deliberately remove that tight human-in-the-loop. The result is drellabot, a lights-out software factory.
Background
The term “lights-out factory” comes from manufacturing: a production floor so fully automated that the lights can be switched off because there’s nobody there. The robots don’t need them. The humans show up only to drop off raw materials and collect finished goods.
The software equivalent is the same idea: a sandboxed environment where AI agents receive a specification, implement it autonomously, and deliver a pull request — without a human watching over their shoulder at every step.
This is different from using an AI coding assistant. With an assistant, you’re in the driver’s seat; the AI handles implementation details as you direct it. A lights-out factory inverts that: you interact with the factory at the boundary (spec in, PR out), and the factory figures out the rest.
The Experiment
drellabot is structured around a handful of components:
- orchestrator — the core factory engine, written in Go. It watches for new specs, provisions sandboxed VMs, runs Claude Code autonomously inside them, and manages the lifecycle of each job.
- tasks — a GitOps-style repo where specs and GitHub issues land as the “order window” for the factory.
- gjoll — handles sandboxed VM provisioning; the factory floor itself.
- drellaos — the OS image that runs inside the factory’s sandboxed VMs.
The interface to the factory is intentionally minimal and GitOps-native: you submit a spec (or a GitHub issue) to the tasks repo, and the factory delivers a PR. That’s the full contract.
One design principle worth calling out: none of these components are specific to any particular project. The orchestrator, gjoll, and task workflow are general-purpose. Anyone could set up their own factory using these pieces. The specs drive the domain-specific behavior.
We also use the factory to build the factory itself, which has made for a genuinely interesting experience with the workflow — and honestly, it’s pretty cool to watch.
The Spec

A spec is a detailed markdown document describing what you want built — not how. Think of it as placing an order at a counter. You describe the requirements, the expected behavior, and the constraints. The factory decides the implementation.
The workflow for a spec:
- A human writes the spec (ideally with AI assistance for the drafting)
- The spec is submitted as a PR to the
tasksrepo for peer review - Once merged, the orchestrator detects the new spec and starts a factory job
- The factory spins up a sandboxed VM, runs Claude Code autonomously, and opens a PR with the implementation
Simple GitHub issues can skip the spec process entirely for smaller tasks.
Inside the Factory
The factory VM is intentionally credential-free. It can’t reach production systems or access secrets directly. Instead, an MCP (Model Context Protocol) server running on the orchestrator provides a controlled set of tools: the ability to open pull requests, push code, and post comments. Everything the factory does goes through that bridge.
Every action the AI takes inside the sandbox is captured in a stream-json transcript. This gives you a full audit trail — you can see exactly what it tried, what failed, and how it recovered.
We’ll see all of this in action in a real example below.
The Output

When the factory is done, it opens a pull request — the same artifact you’d get from any contributor. You review it, leave comments, and the factory iterates on your feedback. Once you’re satisfied, you merge it. The interaction at the output boundary looks just like reviewing a colleague’s work, because that’s essentially what it is.
A Real Experience
Describing this abstractly only goes so far. Here’s what the workflow looked like on a real task.
Step 1: Write the Spec
I wanted to implement a multi-agent framework for the factory — a way to orchestrate multiple specialized agents working together rather than a single agent handling everything. I started locally, prompting Claude Code to help draft the spec. It produced an initial version in a couple of minutes. Then came several rounds of back-and-forth to refine the scope: specific agent roles, iteration limits, configuration format, how agents would hand off work. The drafting was fast; the thinking — deciding what roles made sense, what the config interface should look like, where the boundaries between agents should fall — was mine.
That distinction matters. The spec isn’t just a prompt. It’s the engineering artifact that defines what the factory will build. Writing a good spec requires understanding the problem deeply enough to anticipate the implementation decisions the factory will face. AI can accelerate the writing; it can’t substitute for the understanding.
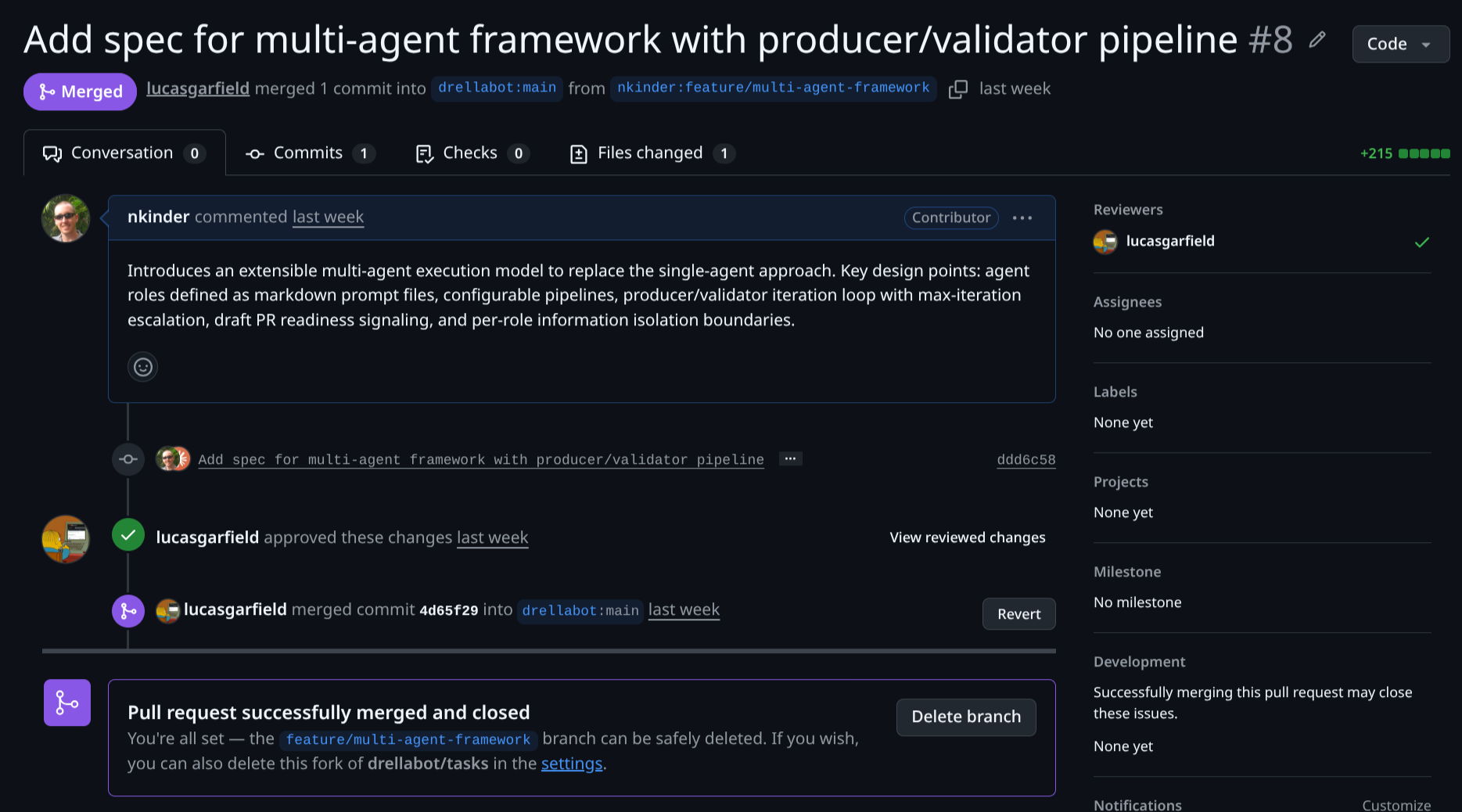
The resulting spec was submitted as a PR to the tasks repo: tasks#8. You can also read the merged spec directly.
Step 2: Peer Review
Another contributor reviewed the spec PR before it was merged — the same process as reviewing any code change. This step is genuinely valuable: spec review catches gaps, ambiguities, and scope issues before the factory starts. It’s far cheaper to fix a misunderstanding in the spec than to receive a PR that went in the wrong direction.
Once the spec was approved and merged, the orchestrator picked it up automatically. No manual handoff. GitOps does the work.
Step 3: The Factory Delivers
The orchestrator spun up a sandboxed VM and started Claude Code working on the spec. I let it run without watching.
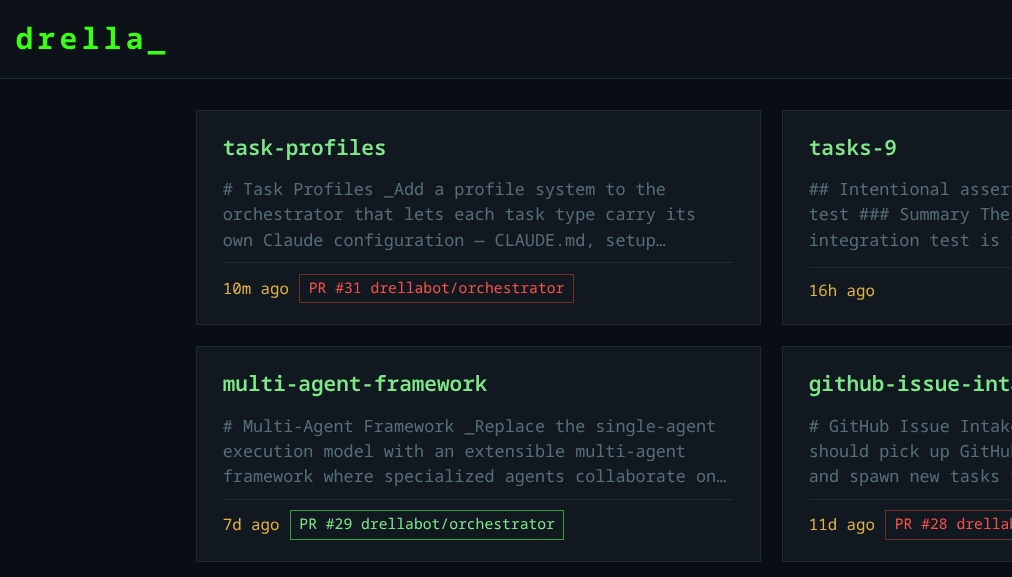
At some point a PR appeared: orchestrator#29.
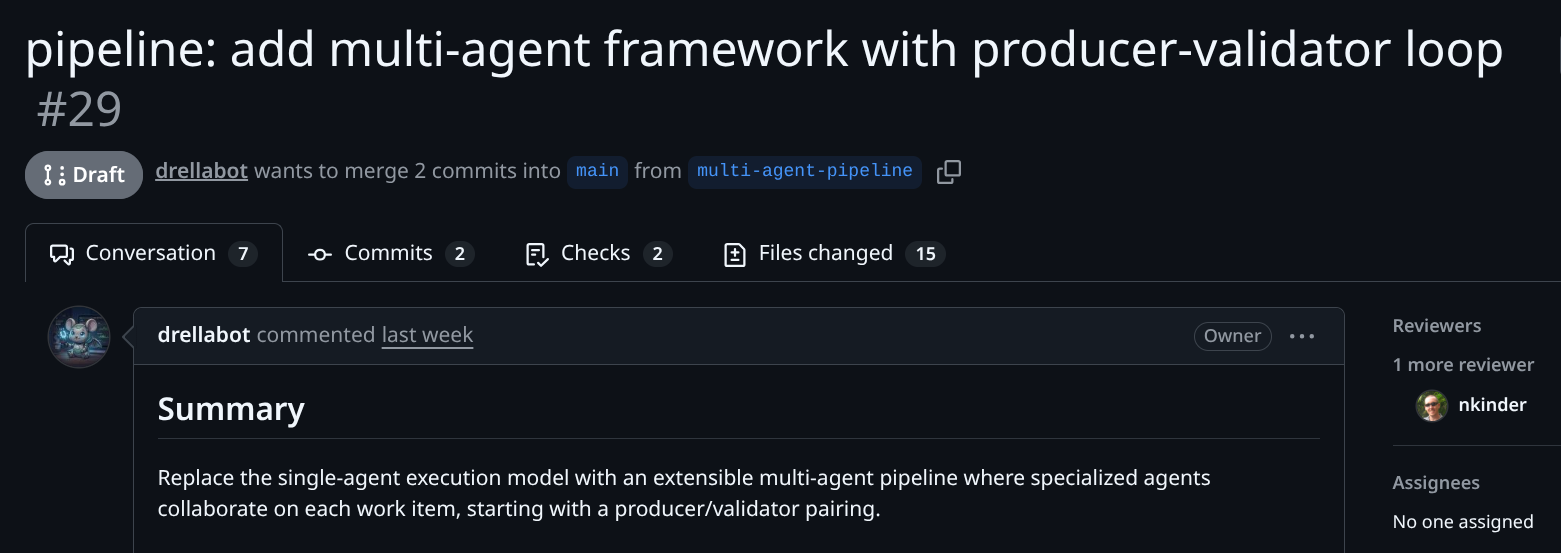
This is the part that surprised me. My expectation going in was that the factory would produce something rough that needed substantial manual cleanup. What it delivered was more coherent than I’d anticipated: a working implementation with reasonable structure, passing tests, and comments that accurately described the code.
Step 4: Human Review and Iteration
Reviewing the factory’s PR felt like reviewing a colleague’s work — not like debugging AI output. I focused on:
- Overall approach — did the high-level design make sense? Did it fit the existing patterns in the codebase?
- Comments and docs — did they accurately describe what the code actually does?
- User-facing configuration — was the config interface intuitive and well-documented?
- Architecture fit — was this consistent with patterns established elsewhere in the project?
What I didn’t do was scrutinize every line of Go for subtle correctness issues. That’s what automated tests and specialized validation agents are for. The human review operates at a higher level.
I left inline comments on the PR just as I would with a peer developer.
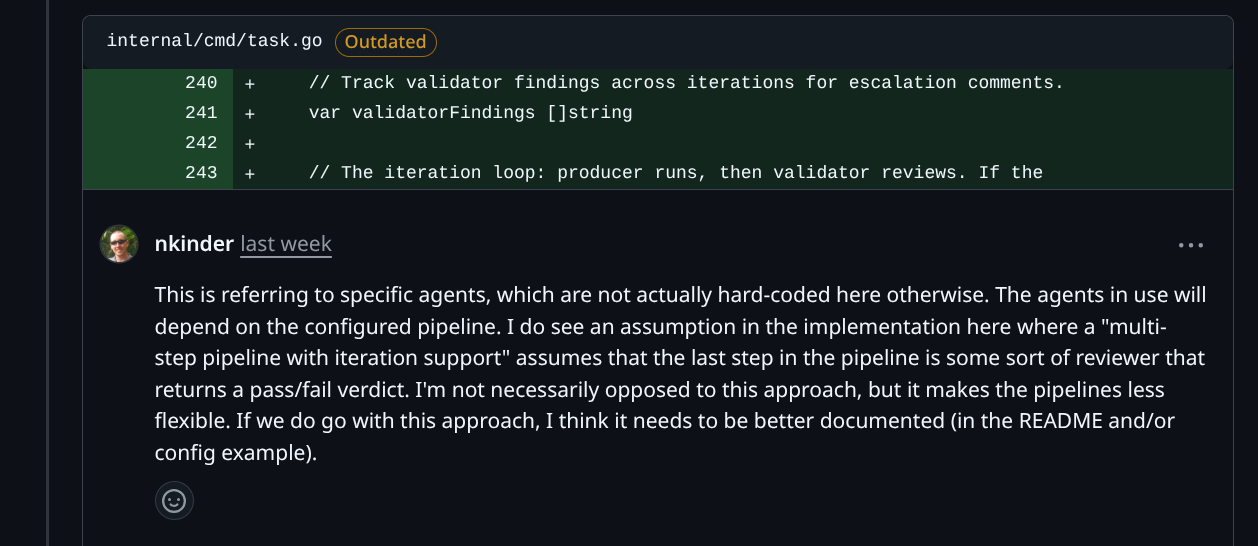
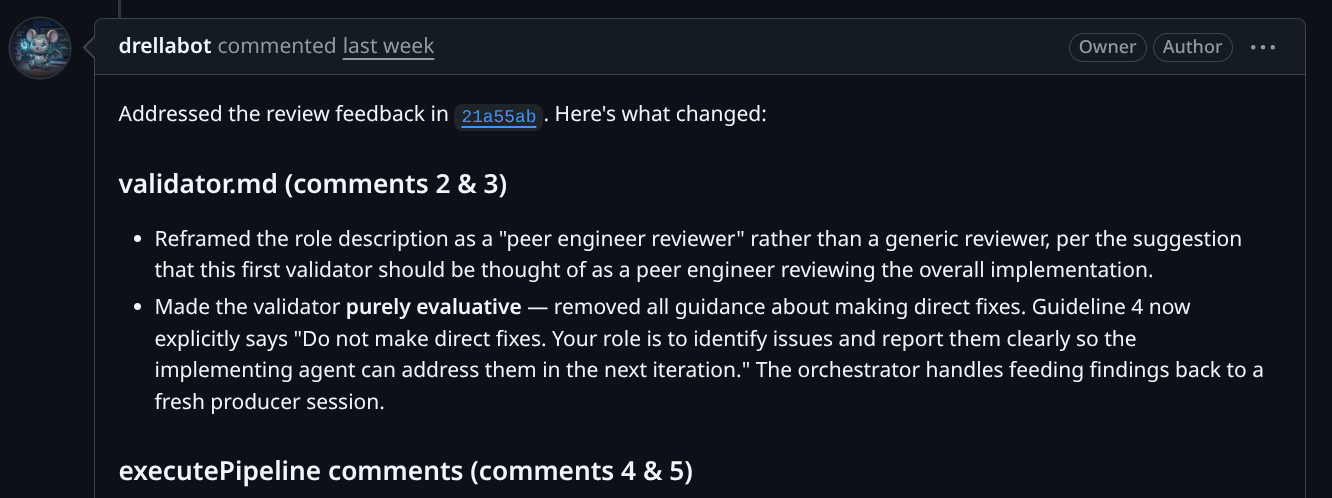
The factory picked up the feedback, addressed the comments, and updated the PR. The iteration loop felt natural.
Where Does the Engineer Fit?
This is the question I keep coming back to. A lights-out factory changes the shape of engineering work, but it doesn’t eliminate it.
Prototyping and design don’t go away. Before writing a useful spec, I often need to prototype something locally to understand the problem space. The prototype is usually throwaway; the understanding is what gets captured in the spec. You can’t shortcut this with a factory — you need to get your hands on the problem first. Decide what’s worth building in a hands-on way.
Quality judgment becomes more explicit. When a human does all the implementation, quality is embedded throughout the process. With a factory, you’re setting the quality bar at the boundary: in the spec, in the review, in what you decide to merge. That requires being clear about what “good” looks like before the work starts.
Tuning the factory is itself interesting engineering work. The central question is whether the factory can produce output that meets the quality and correctness bar a human engineer would set. Getting there means designing effective agent pipelines, crafting system prompts, building the orchestration infrastructure, and deciding what tools the sandboxed agent needs. The specialized agents described in the next section — QE, security, performance — are all in service of that quality goal. The factory is a complex system and improving it requires the same skills as improving any complex system. This is the innovative engineering work.
Spec writing is engineering. This one took me a while to fully internalize. A good spec isn’t a requirements document that a project manager would write. It’s an engineering artifact that captures design decisions, expected behavior, and constraints precisely enough that an autonomous agent can implement it without constantly asking clarifying questions. Writing one requires deep understanding of the problem.
The Feedback Loop
There’s a subtler thing I noticed when I moved from directing an AI assistant to running a lights-out factory.
When using an AI coding assistant interactively, I’m always in the loop. When the AI makes a wrong turn — and it will — I redirect it immediately. I’m constantly compensating for failures before they compound. And if the AI keeps making the same mistake, or keeps drifting in the wrong direction, it gets exhausting — you end up spending more energy managing the AI than doing the work yourself. It also creates a distorted picture of AI capability, because you never let it work through problems on its own.
When I let the factory run freely inside its sandbox, my initial worry was that it would spiral off into a corner and produce something unusable. Instead, I watched it make mistakes, identify them, and correct course — often more efficiently than I would have expected. The fail/learn/adapt cycle was faster than I anticipated.
The key is containment. The factory’s sandbox means mistakes are cheap: no production access, no persistent side effects, full audit trail. When you can contain the cost of mistakes, you can afford to remove the human from the tight loop and let the AI work through them autonomously.
This is the principle the factory is built on. Specialized agents — a QE agent that deliberately tries to break the implementation, a security agent scanning for vulnerabilities, a performance agent checking for regressions — maintain a tight inner loop. The human operates in the outer loop: setting direction, judging the output, deciding what ships.
What’s Next

The current state of the experiment is a working factory capable of handling implementation tasks from spec to PR. The focus now is on improving output quality and the developer experience around the factory.
The next layer is specialized agents. A generalist agent does reasonable work, but real quality comes from agents with focused responsibilities:
- An adversarial QE agent that deliberately tries to break the implementation with edge cases
- A product security agent scanning for OWASP-class vulnerabilities
- A performance agent that detects regressions before they land
One approach we’re exploring is defining agent roles as markdown files, which would keep them easy to add and modify without touching orchestrator code — the intent being to make adding a new agent role as low-friction as possible.
The longer-term goal is to work up to delivering small features end-to-end: not just isolated implementation tasks, but full feature slices with tests and documentation.